We Built a Slack Bot for Valet Parking Services: 🅿️art 2 | The Logic
Part two of the joint project with my intelligent and brave wife, Olga!
This post is a part of a series, so [check out part 1 for context] (../building-a-slack-bot-with-python-on-gcp).
Warning: As our development of this project was a little “all over the place” as we try to fit it to our busy lives and the Holiday Season, the blog post is a little all over the place as well.
QoL improvements
Before moving on the the next big tasks, we wanted to do some small QoL improvements, which we introduced in 3 separate PRs.
Slimming down the Docker Image size
This one even got a tweet.
Made my Docker image size 20% (from almost 1GB to 196MB) by adding `-slim` to the base image. Sane defaults, anyone? pic.twitter.com/6yt17kEWpo
— Shay Nehmad (@ShayNehmad) September 10, 2021
Sometimes things don’t make sense to me. Why is the DEFAULT image the one with “batteries-included”, all the bloat, and the huge one? Do developers really prefer things to surface-level work so badly that they are willing to accept images that are 5 times bigger as the default? 🤔
In any case, the diff was very simple:
--- Dockerfile.base 2021-09-11 15:35:49.117069816 +0300
+++ Dockerfile.1 2021-09-11 15:34:10.003008547 +0300
@@ -1,3 +1,4 @@
# Base image. This version is in the pyproject file as well.
-FROM python:3.9
+# See Image Variants on https://hub.docker.com/_/python
+FROM python:3.9-slim
Shoutout to Will Schenk for the awesome
diffshortcode. If you have time after reading this blog, make sure to put Will’s on your read list. Very cool technical musings there!
Adding a test endpoint to the server, to make sure it works
We started by writing a very simple pytest, which just sent a request to the
first endpoint we’ve developed, called spots. But then, we realized that once
we actually develop that endpoint, the return value will change. So to keep
things humming nicely, we added a /test URL to the server which we used for
the test.
src/valet_parking_slack_bot/server.py.1:
--- server.py.base 2021-09-11 15:49:18.844449939 +0300
+++ server.py.1 2021-09-11 15:49:26.696418007 +0300
@@ -1 +1,2 @@
+from datetime import datetime
from flask import Flask
@@ -4,3 +5,2 @@
-
app = Flask(__name__)
@@ -18,3 +18,11 @@
+@app.route('/test/healthcheck', methods=['GET'])
+def healthcheck():
+ response = {
+ "message": "I'm alive!",
+ "ts": str(datetime.now())
+ }
+ return response
+
if __name__ == "__main__":
- app.run(debug=True, host="0.0.0.0", port=int(environ.get("PORT", 5000)))
\ No newline at end of file
+ app.run(debug=True, host="0.0.0.0", port=int(environ.get("PORT", 5000)))
This is the updated test, where you can see the TODO was deleted. One of the best feelings is checking boxes ✅
tests/test_service_availability.py.1:
--- tests/test_service_availability.py.base 2021-09-11 15:53:42.271063485 +0300
+++ tests/test_service_availability.py.1 2021-09-11 15:53:22.591186320 +0300
@@ -1,2 +1,5 @@
import requests
+import logging
+
+logger = logging.getLogger(__name__)
@@ -4,9 +7,11 @@
-# TODO: Add a "healthcheck" endpoint to the app,
-# since the response to this URL will change and the
-# test will fail even though the service is available!
def test_cloud_endpoint():
- want = "no spots for you!"
- response = requests.get(service_cloud_url + "/spots")
+ test_url = f"{service_cloud_url}/test/healthcheck"
+
+ response = requests.get(test_url)
+
assert response.ok
- assert want.lower() == response.text.lower()
+ data = response.json()
+ assert data["message"] == "I'm alive!"
+ assert data["ts"]
+ logger.info(f"requested {test_url}, got {str(data)}")
and it works!

Adding basic CI
We added some basic CI tooling using GitHub Actions, which you can check out
here. The
CI currently runs flake8 and pytest. We based it off of GitHub’s official
Python Application
with only some minor changes for Poetry:
# This workflow will install Python dependencies, run tests and lint with a single version of Python
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
name: Python application
on:
push:
branches: [ dev ]
pull_request:
branches: [ dev ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.9
uses: actions/setup-python@v2
with:
python-version: 3.9
- name: Setup Poetry
uses: Gr1N/setup-poetry@v7
- name: Test poetry installation
run: poetry --version
- name: Configure poetry
run: |
poetry config virtualenvs.create false
poetry config --list
- name: Install dependencies
run: |
poetry install
- name: Lint with flake8
run: |
# stop the build if there are Python syntax errors or undefined names
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
- name: Test with pytest
run: |
pytest
Setting up a local development environment
Last time, we managed to deploy our bot to the cloud. Immediate regret followed, as the build-deploy-test loop got a lot longer! Instead of just changing the code to see what happens, we now need to deploy the code to GCP, build a new docker image there, and deploy it. That’s too much time!

To speed things up, we used ngrok to set up a public URL for our local web server, and then configured the Slack app to go to that URL instead of our cloud endpoint. When we’ll release, we’ll need to revert this change.
After downloading ngrok, running it was literally just ./ngrok http 5000.
The command gives you a public URL:

And then you configure it in Slack:

Designing and Building the Bot’s Business Logic
With all the POCs we did in the first post and all the QoL improvements out of the way, now we finally feel comfortable enough with the infrastrcture and the build-deploy-test loop to get cracking with developing the core logic of the app!
Let’s do some Product - designing the user flows
One thing we’ve learned since last time with some user surveys was that setting up Google Calendar resources is a total pain, so we need to manage the repository ourselves. With this architectural change in mind, we wanted to design the first user interaction with the bot - setting it up.

Side note: To do this part well, we’ve used a tool I really started to like recently - Excalidraw. It’s the best virtual whiteboard experience I’ve had so far, and I pretty much tried them all.
The bot seems very simple on the surface. You ask it to reserve a spot, it reserves a spot, right? How complex can it be? When starting to actually work on planning the user flows with a DDR, we’ve discovered multiple layers of complexity:
- Setup - how to set the bot up in a self-serve way that isn’t horrible?
- Edge cases - someone wanted to park, but now they can’t make it? Add new spots when expanding? Etc.
- UX - Do we really want to only use
/commands? The main drawback is that bot usage will be mostly from mobile devices (since people reserve parking before they make it to the office). Typing/on a mobile device is annoying. - Account management - we only thought about one user, but the bot will hopefully serve multiple Slack Workspaces. At the very least, it’ll serve the first client and the dev env.
Here’s what we came up with. You’ll need to click the image to scroll around and actually read it:
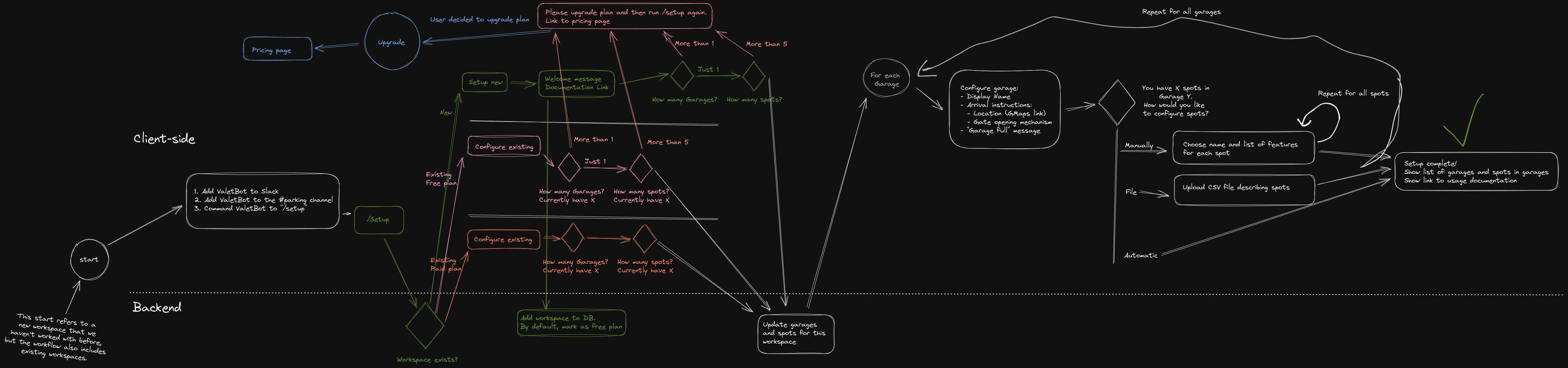
Since we saw that even just the setup flow is pretty complicated on its own, we decided to implement a little bit more of the bot so we have better domain knowledge before designing the other user flows. It seemed like learning more about Slack bots, designing the code itself a little more, and seeing what’s easy and what’s hard were better avenues to getting a better end product than spending time designing the rest of the flows.
Initial development - design, mocks, stubs
In our initial design, we went for a pretty simple design, mostly meant to make sure we’re adhereing to the Single Responsibility Principle and to expedite development using this trick:
Create an interface for the parking spot repository, so that developing
it won’t block us from working on business logic and UX.
Our design ended up here:

This design also allowed us to test the designator using automatic spec for mocks, which proved very useful in our case. Check out how clear and clean these tests are!
from valet_parking_slack_bot.logic import ParkingSpotDesignator
from valet_parking_slack_bot.repo import ParkingSpotRepoBase
from unittest.mock import MagicMock, create_autospec
test_username = "test_user"
def test_reserve_spot_sanity():
# arrange (given)
repo = create_autospec(ParkingSpotRepoBase)
repo.retrieve_available_spots.return_value = [1]
designator = ParkingSpotDesignator(repo)
# act (when)
return_value = designator.try_reserve_spot(test_username)
# assert (then)
assert return_value
repo.retrieve_available_spots.assert_called_once()
repo.assign.assert_called_once_with(test_username, 1)
class TestReleaseByUsername:
def test_one_reserved_spot(self):
repo = create_autospec(ParkingSpotRepoBase)
repo.retrieve_spots_by_user.return_value = '1'
designator = ParkingSpotDesignator(repo)
return_value = designator.release_by_username(test_username)
assert return_value == "Parking spot 1 has been released successfully"
def test_no_reserved_spots(self):
repo = create_autospec(ParkingSpotRepoBase)
repo.retrieve_spots_by_user.return_value = ''
designator = ParkingSpotDesignator(repo)
return_value = designator.release_by_username(test_username)
assert return_value == "User had no assigned parking"
def test_two_reserved_spots(self):
repo = create_autospec(ParkingSpotRepoBase)
repo.retrieve_spots_by_user.return_value = '1 2'
designator = ParkingSpotDesignator(repo)
return_value = designator.release_by_username(test_username)
assert return_value == "You have several reserved spots: 1 2. Which one to release?"
These tests do a TON for the designator without worrying even ONCE about
the repository! They tell us a lot about how the interface works and what
the designator is doing. They help maintain it on a deeper level than “it’s
not working”.
Cool! Since we also implemented a stub, the bot now responds with semi-coherent responses, which is very exciting as well:
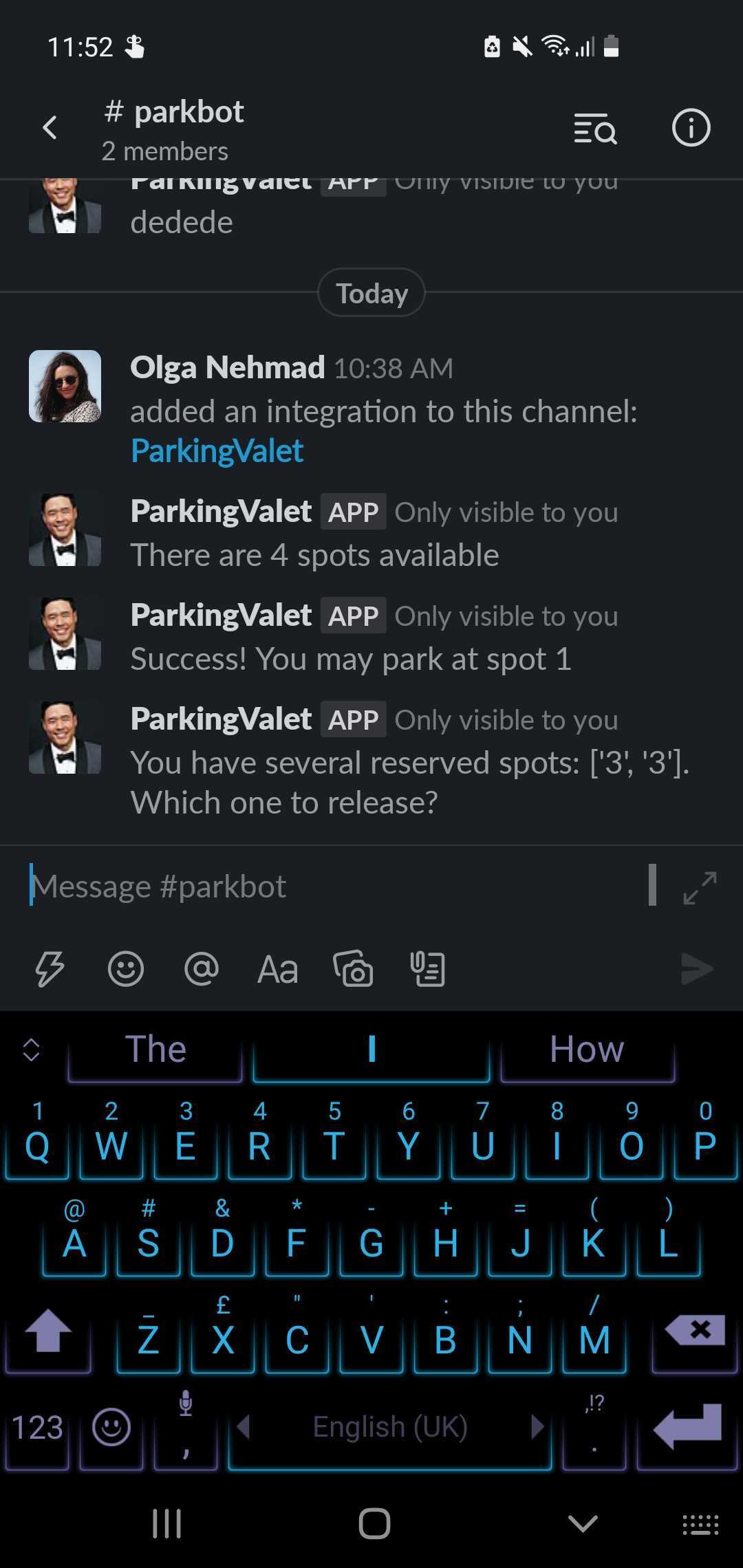
Let’s do some Development - using Bolt
The first version of the bot was based on Flask, but the moment we wanted to
do something that was actually Slack-ish (in our case it was extracting the
user’s name based on the context in the request, which includes the user_id)
we felt like it was difficult.
After looking around a bit we’ve found Bolt SDK for Python, which seems packed with great features, useful documentation, and easy to use. We migrated the functions we’ve implemented on Flask to use Bolt, instead. We’ve still kept Flask as the Web server, so that the test endpoint (remember? From the last post) will still work.
Let’s get sidetracked - Web servers, web applications, and WSGI
Why does the Bolt documentation say:
By default, Bolt will use the built-in
HTTPServeradapter. While this is okay for local development, it is not recommended for production.
And why, when you run flask run, it tells you:
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
And what does that have to do with Whiskey?
Well, since Olga was curious about it, we learned more about WSGI. Instead of parroting it all here, I’ll try to summarize what we’ve understood from PEP 3333:
- There are two parts of a complete web app: the app (which is what we care about) and the server (which, honestly, is not what we care about right now).
- To allow an app to pick-and-choose which server they want to use for different use cases (development VS huge production cases), the WSGI is an agreed-upon protocol.
- Flask allows you to write WSGI-compliant apps. It also comes with a server, but that server is mostly for development.
- There are a lot of Production-grade server stacks - seems like for Python, Gunicorn with nginx is a good choice.
After spending some time in this rabbit hole, we decided we actually don’t care about it enough at this point, and we’ll stick with Flask and Bolt.
In the future, we’ll consider migrating to the following stack:
nginx <-> gunicorn <-> flask <-> bolt
So this was completely unnecessary sidetrack. Aren’t those the best? Just ask CGP grey.
Next up
Next time, we plan to work on:
- Listening to messages instead of slash commands to improve UX
- Using Blocks to create beautiful looking responses
- Develop an implementation of the repository using Cloud SQL
Stay tuned!